
Værdata satt i system
Skrevet av: Espen Solli GrandeUtgangspunktet:
Vi begynner med det viktigste først; analyse av datamengden som skal behandles. Selve værsystemet kan ta seg av maks 3 værstasjoner per dashboard, og disse skal oppdateres hvert 5 sekund. Med andre ord så lagres det mye data kontinuerlig. Samtidig hentes det ut data som behandles til diverse formål. For eksempel henter vi ut en samlet feed fra alle stasjonene hvert 5. sekund som vises som aktuelle tall på framsiden. Historiske data skal også behandles for å kunne vise grafer over forskjellige tidsperioder, og vise rekorder. Alt dette krever forskjellige fremgangsmåter og løsninger for henting og behandling.
En viktig del av jobben er å lage et godt og forståelig design. Vi tok en kikk på hva som allerede eksisterte i dag i diverse løsninger - og fant fort ut at det var mye variert og «overlesset» design, som gjerne skal se «ekte» ut.
Her er noen eksempler:


De fleste målerne har mye informasjon, mange unødvendige detaljer og mye design. Vi fokuserte derfor på å lage et design som er mer stilrent og som framhever dataene på en tydelig måte.
Design
Designbruken ovenfor avslører at det ikke tenkes nok funksjonell design når værdata skal presenteres. Man har ofte mye tekst, mange forskjellige farger og former som tar oppmerksomheten bort fra tallene. Derfor ønsket vi å løfte fram dataene og tone ned resten. Samtidig ville vi ta vare på trendvisning og andre visere der det var fordelaktig. Her er noe av det vi kom opp med:


Her er tall og den viktigste informasjonen i fokus. Noen har soner innebygd i designet for å vise når det er varmt, kaldt eller hvor vinden kommer fra. Noen har også piler for å vise trender. Her kommer også rekorder for alle målerne inn. Dersom man trykker på "i"-en opp i hjørnet på hver måler får man opp en trendgraf for det siste døgnet samt rekorder som er registrert:
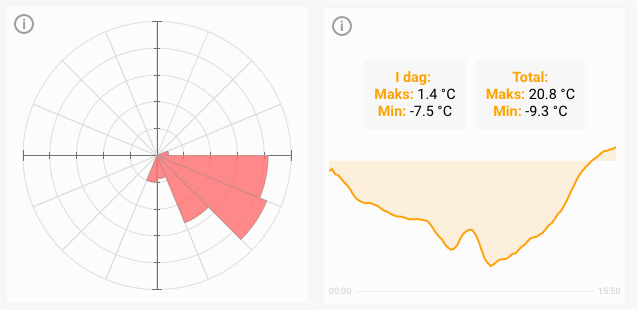
Her kan vi se hvilken retning det har blåst mest i det siste. Til høyre vises en graf for hvordan temperaturen har vært i en viss periode, samt rekorder i dag og totalt for måleren.
Rekordene og trendgrafene er skjult til å begynne med. Årsaken er at vi anser dette som sekundær informasjon som ikke behøver å være direkte synlig ved første øyekast, men som bør være tilgjengelig for spesielt interesserte.
Vi synes også det er viktig å få inn noen animasjoner for å skape en mer interaktiv følelse, og vise at det skjer noe når nye data hentes inn. Her har vi valgt å animere noen målere for å vise graden av info. Dersom det regner mye kommer det opp flere vanndråper, og animasjonen går raskere. Det er også laget varsel-animasjoner dersom verdiene nærmer seg farlige verdier; måleren begynner å blinke for å vise at det kan være farlig vær i vente.
Denne viser vind fra lite vind til storm styrke
Denne viser null nedbør til flom
Utfordringen
En av de store utfordringene med denne typen jobber er å få behandlet all dataen som er samlet inn, og vise den på en fin måte ved hjelp av grafer og målere. Bak denne jobben ligger det mye planlegging og optimalisering av koden opp mot database og behandlet data.
Her prøver vi å holde databasespørringene til det minimale, og forsøker å kombinere dem slik at det blir minst mulig press på serveren. På én og én stasjon har ikke dette så mye å si, men dersom det er mange spørringer som skjer hele tiden vil hver optimalisering i spørringene spare masse kraft på serveren.
Her er et eksempel: La oss si at vi skal hente verdier fra 3 stasjoner til et dashboard og kjører disse hver for seg. Hver av disse må koble seg til, hente data, behandle dem og slå dem sammen med de andre koblingene. Om man i stedet samler de til én vil denne koble til én gang, behandle disse og de kan brukes videre. Så om vi har 1000 koblinger til dashboardet vil det første scenarioet koble til 3000 ganger, mens nr. 2 bare gjør det 1000 ganger. Dette er en tredobling av koblinger, som sliter på serveren. Og dette er bare på ett dashboard. Om man tenker man har mange som blir brukt samtidig er dette masse kraft som går til spille.
I tillegg til å optimalisere databasespørringene mellomlagrer vi resultatene som blir gitt og behandlet via spørringene. Caching, som dette heter, er ganske enkelt en fil som lagrer resultatet. Så neste gang man prøver å hente samme spørring vil man få filen istedet. Dette avlaster serveren enormt, da det eneste som sjekkes er om mellomlagringen fortsatt er gyldig, og som da serverer cache-filen.
Vi kan ta et annet eksempel: Om det er 1000 koblinger til dashboardet så vil den første koblingen hente verdiene og lagre den i en fil. De neste 999 koblingene vil hente denne filen, med andre ord sparer vi serveren for 999 koblinger og behandling av data. Dette er en enorm ressurssparing for serveren.
I tillegg til dette lagres alt i JSON-format som kan leses av mange programmeringsspråk og det er enkelt å bruke og behandle denne dataen igjen.
Og her kan vi se sluttresultatet
Når vi har knyttet design og henting av alle data og satt det i system får vi resultatet som vises under: