Mustasj
Tjenester
Arbeid
Folk
Fag
Ta kontakt
Meny
Fag
Erfaringer, meninger og eksperimenter fra folk som jobber med design og teknologi hver dag.
3 siste artikler
Hva deler du med KI?
KI
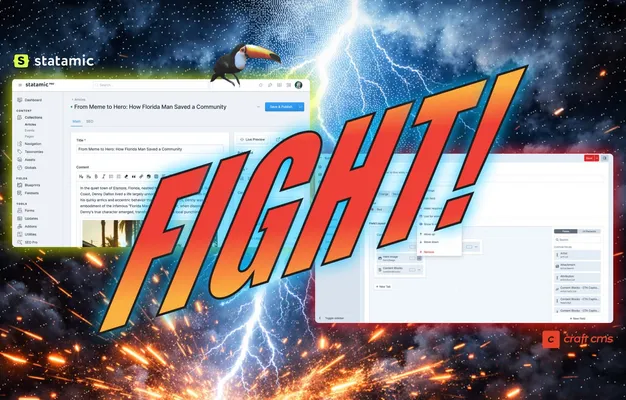
Kan Statamic CMS erstatte Craft CMS?
CMS
Kunstig intelligens som arbeidsverktøy i Mustasj
AI
Alle
KI
CMS
AI
Oppskrift
Hva deler du med KI?
KI
Kan Statamic CMS erstatte Craft CMS?
CMS
Kunstig intelligens som arbeidsverktøy i Mustasj
AI
Heimbakakak: Et eksperiment på oppskrifter
Oppskrift
Vi tester MCP - når KI integreres i arbeidsflyten
AI